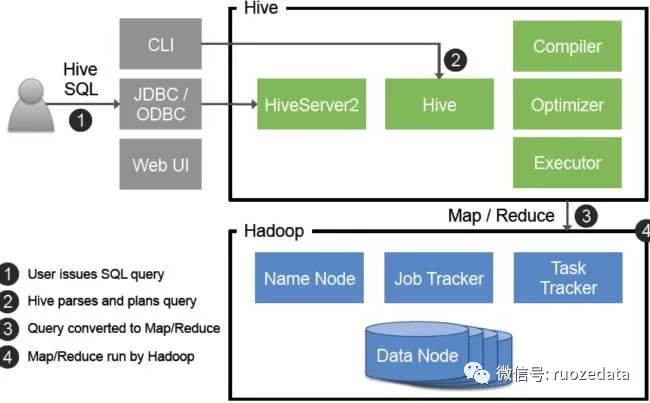
1. 介绍:
两者都允许远程客户端使用多种编程语言,通过HiveServer或者HiveServer2,
客户端可以在不启动CLI的情况下对Hive中的数据进行操作,
两者都允许远程客户端使用多种编程语言如java,python等向hive提交请求,取回结果
(从hive0.15起就不再支持hiveserver了),但是在这里我们还是要说一下HiveServer。
HiveServer或者HiveServer2都是基于Thrift的,但HiveSever有时被称为Thrift server,
而HiveServer2却不会。既然已经存在HiveServer,为什么还需要HiveServer2呢?
这是因为HiveServer不能处理多于一个客户端的并发请求,这是由于HiveServer使用的Thrift接口所导致的限制,
不能通过修改HiveServer的代码修正。
因此在Hive-0.11.0版本中重写了HiveServer代码得到了HiveServer2,进而解决了该问题。
HiveServer2支持多客户端的并发和认证,为开放API客户端如采用jdbc、odbc、beeline的方式进行连接。
2.配置参数
Hiveserver2允许在配置文件hive-site.xml中进行配置管理,具体的参数为:
参数 | 含义 |
-|-|
hive.server2.thrift.min.worker.threads| 最小工作线程数,默认为5。
hive.server2.thrift.max.worker.threads| 最小工作线程数,默认为500。
hive.server2.thrift.port| TCP 的监听端口,默认为10000。
hive.server2.thrift.bind.host| TCP绑定的主机,默认为localhost
配置监听端口和路径
1 | vi hive-site.xml |
3. 启动hiveserver2
使用hadoop用户启动
1 | [hadoop@hadoop001 ~]$ cd /opt/software/hive/bin/ |
4. 重新开个窗口,使用beeline方式连接
- -n 指定机器登陆的名字,当前机器的登陆用户名
- -u 指定一个连接串
- 每成功运行一个命令,hiveserver2启动的那个窗口,只要在启动beeline的窗口中执行成功一条命令,另外个窗口随即打印一个OK
- 如果命令错误,hiveserver2那个窗口就会抛出异常
使用hadoop用户启动
1 | [hadoop@hadoop001 bin]$ ./beeline -u jdbc:hive2://localhost:10000/default -n hadoop |
使用SQL
1 | 0: jdbc:hive2://localhost:10000/default> show databases; |
5.使用编写java代码方式连接
5.1使用maven构建项目,pom.xml文件如下:
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" |
5.2JdbcApp.java文件代码:
1 | import java.sql.Connection; |
